¶树结构
¶概念解释:
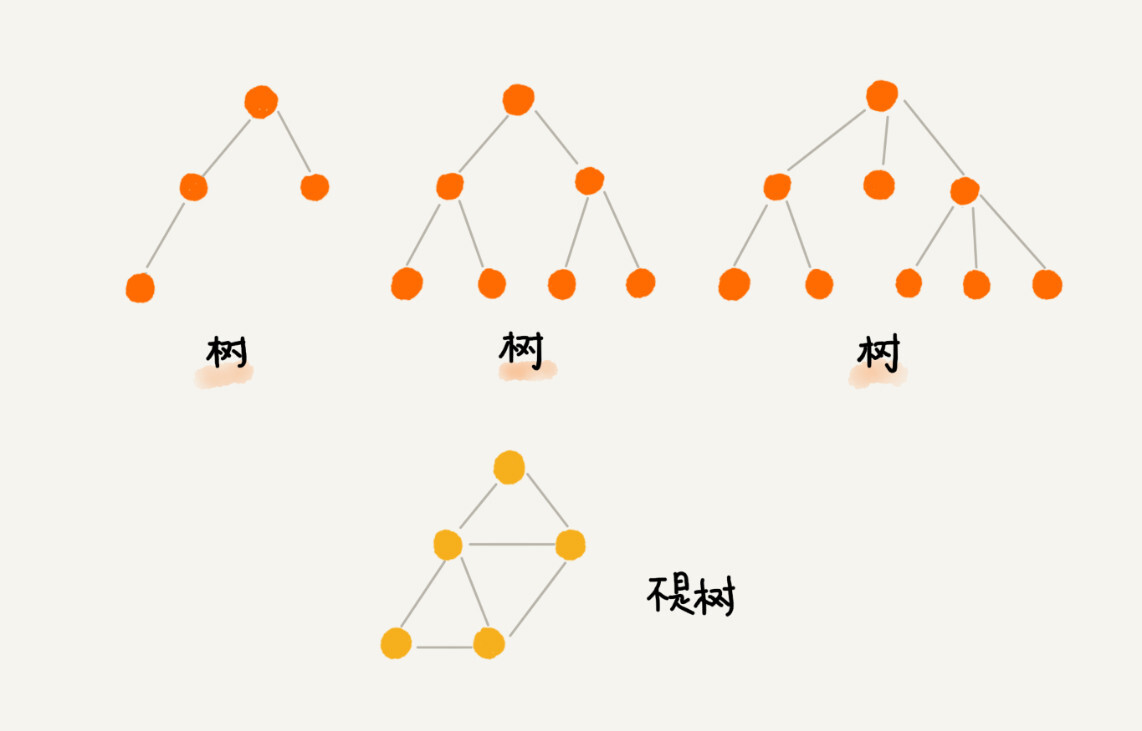
树的结构和现实中的树是类似的:具备根,枝干,叶子等,只不过在树结构中,这些被对应转换成了根节点,节点之间的边以及子节点这些概念,用图来展示会比较直观:
图中这种由一个根节点向下延申出来子节点,然后子节点继续向下延申直到没有节点,且每个节点的同一层节点没有直接联系,这种结构就是树
数结构有三个比较重要的属性:
高度:树结构的每个节点都具备高度属性,节点的高度等于节点到叶子节点的最长路径(边数)
深度:根节点到这个节点的边数
层数:节点的深度+1
树的高度 = 根节点的高度
我们知道数组中的数据存放在指定下标位置,预先知道下标,可以直接访问到该数据。而散列表也是基于数组的随机访问特性,根据需要存储的数据的键(key),使用特定的散列函数(hash(key))计算出该键值对应存储的下标位置
散列函数可以联想一下HashMap的hash函数:
1 |
|
在HashMap中存放元素时,需要先通过hash函数确定元素的key映射出来的下标位置,JDK1.8中HashMap的hash函数是通过 key 的hashCode 和自身右移16位之后的值进行异或 , 得出一个新的hashCode作为key对应的下标位置
将 key.hashCode()的值和自身右移16位进行异或,也就是将自身的高位和低位进行异或运算(相同为1,不同为0),加大低位的随机性
二分查找也叫做折半查找,是一种在有序数据序列中进行指定数据位置查找的算法,方式是每次取数据序列的中间值和将要查找的值进行对比,因为数据有序,所以要么这个中间值大于目标值,可以继续以同样的方法向右查找;小于目标值则同理向左查找,直到找到目标值的位置或者数据不存在。
光从思路来看有分治法的影子:对于每一段数据范围的查找思路都是相同的,取中间值判断,然后决定下一次搜索的数据范围,再以同样的方法判断。
从效率的角度上来说,对于一个 n 长的数组,要查找指定值的位置,可以顺序从头至尾遍历,这样操作的时间复杂度就是O(n);而二分查找则每次都将查找范围缩小一半,从 n 到 n/2 ,n/4,n/8…n/2^k ,效率提升十分明显
不要只管低着头走,一定要记得抬头看看方向
分析
就这点仔细地想了一下 : 有时候在知道正确方式的情况下,还选择了错误那个,明知故犯要么出于感性,要么出于懒惰了—思维上的懒惰—不愿意认真,慢慢地动脑去思考,这是病,不能惯着
这里得套用陈皓老师的一段观点
学习是一件“逆人性”的事,就像锻炼身体一样,需要人持续付出,会让人感到痛苦,并随时想找理由放弃《左耳听风》
得承认,打游戏的我笑得很开心,但那只是虚拟游戏,而不是人生这个现实游戏
急于求成 : 因为之前在王峥老师课程的学习都是尽量维持着一天一学,学完就总结并配合实践这样的顺序来的,而前面的东西因为并没有深入学习,所以也没有多少难度,可以按照计划进行;学到递归的时候发现光看完不去理解,脑子也是一团浆糊,稍微难一点,就不行了
Given a binary tree, determine if it is height-balanced.For this problem, a height-balanced binary tree is defined as:
a binary tree in which the left and right subtrees of every node differ in height by no more than 1
the input : [ 3,9,20,null.null,15,7 ]
1 | 3 |
return true
概念:
实现:
1 |
|
直接从递归算法的特点来说,递归是对不同数据规模的同等类型问题的求解方式,通过将问题分解为子问题,求解子问题以达到解开父级问题的目的
这么说比较绕,引用王峥老师的《数据结构与算法之美》中的递归场景:
当你带着你女朋友(
也不知道你有没有)去电影院看电影,坐在中间某一排的时候,因为太暗了看不清,你女友问你现在坐在第几排,你也不知道,只能问前面的人他们是第几排,然后参照得出你所在的位置;如果你前面的人也不知道自己是第几排的话,他们就需要继续往前一排问;
直到有人可以明确地回答自己所在的排数,最后你就间接得出了自己所在的位置。
这个场景中提到的求解你所在的排数的问题,涉及到几个数据:
将问题转化成代码需要先对问题进行抽象,得出问题的概念模型,王峥老师推荐的方法是:写出递推公式,找到终止条件,剩下的就是将递推公式转换成代码
求解 n 个台阶走法:
存在 n 个台阶,你一次可以跨1步或者2步
求解n个台阶会有几种走法
可能第一反应是脑子里演练这个过程,它的一次次调用是怎样的,最终停止条件又是什么…这样很难得出问题的解法,递归的实现思路和我们思考问题的思路差别挺大,我们无法非常直观地自己展示出这个过程
生产-消费者模型:和栈比较类似,基于数组实现的队列叫顺序队列,是一种有界队列;
而基于链表实现的队列叫链式队列,默认实现是无界队列;
前者在资源控制上应用比较广泛,例如构造线程池的ArrayBlockingQueue(有界阻塞队列)